Hi! I'm Tim Tyler - and today I will be discussing AIXI - a proposed
model for synthetic intelligent agents.
AIXI is a design for constructing intelligent agents which was
originnally developed by Marcus Hutter.
It is largely based around a formalisation of Occam's razor - known as
Solomonoff induction.
Hutter introduces the idea in an abstract as follows:
Sequential decision theory formally solves the problem of rational
agents in uncertain worlds if the true environmental prior probability
distribution is known. Solomonoff’s theory of universal induction formally
solves the problem of sequence prediction for unknown prior distribution. We
combine both ideas and get a parameter-free theory of universal Artificial
Intelligence. We give strong arguments that the resulting AIXI model is the
most intelligent unbiased agent possible. We outline how the AIXI model can
formally solve a number of problem classes, including sequence prediction,
strategic games, function minimization, reinforcement and supervised learning.
The major drawback of the AIXI model is that it is uncomputable. To overcome
this problem, we construct a modified algorithm AIXI-tl that is still
effectively more intelligent than any other time t and length l bounded
agent.
First, I'd like to say that this work is great - and I'm very grateful
for the efforts of Marcus Hutter and Shane Legg in this area.
However, I do have some criticisms - as follows:
The first problem is that AIXI has no representation of its own brain.
Eliezer Yudkowsky has previously pointed this problem out, so - in
his own words:
Ultimately AIXI's decision process breaks down in our physical
universe because AIXI models an environmental reality with which it
interacts, instead of modeling a naturalistic reality within which it
is embedded.
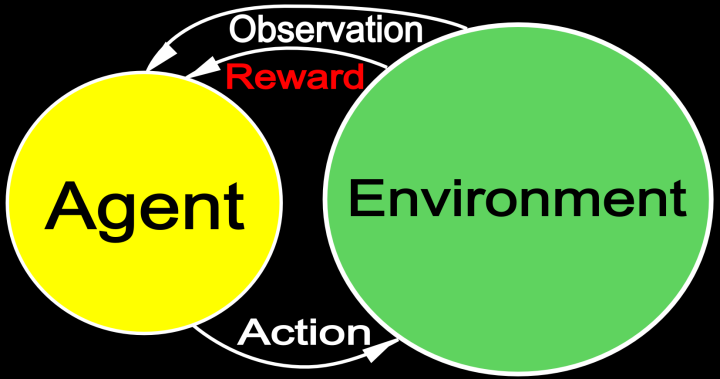
Hutter describes the AIXI agent and the environment as distinct Turing
machines that have "mutually inaccessible work tapes".
Here is a diagram of the situation:
The AIXI agent is not embedded in the same universe as its
environment. Rather it exists in a separate region, and interacts with
the environment via sensory and motor channels.
Why does this matter? Any attempt at implementing AIXI would have to
actually embed the agent within its associated environment. However,
the agent has no conception of the location of its own brain. If you
told it to mine silicon atoms, at some stage, it's mining claws would
take a great chunk out of its own brain - and it would come to a
sticky end.
To function properly, AIXI would have to be told not to injure its own
brain, not to sever any of its sensory or motor cables, and not to
take actions that might endanger its own power supply and support
infrastructure.
While this is a flaw, it is probably not a terribly serious
one. The most obvious remedy is to teach AIXI not to do those
things.
The second problem is the wirehead problem.
Hutter discusses the problem explicitly, as follows:
Another problem connected, but possibly not limited to embodied
agents, especially if they are rewarded by humans, is the following:
Sufficiently intelligent agents may increase their rewards by
psychologically manipulating their human “teachers”, or by threatening
them. This is a general sociological problem which successful AI will
cause, which has nothing specifically to do with AIXI. Every
intelligence superior to humans is capable of manipulating the latter.
In the absence of manipulable humans, e.g. where the reward structure
serves a survival function, AIXI may directly hack into its reward
feedback. Since this is unlikely to increase its long-term survival,
AIXI will probably resist this kind of manipulation (just as most
humans don’t take hard drugs, due to their long-term catastrophic
consequences).
In my view, Hutter is correct in saying that this problem also affects
other agents. However, he is incorrect in claiming that all other
agents are necessarily affected. The argument that intelligent agents
superior to humans are capable of manipulating them is correct, but
the conclusion - that therefore they will manipulate them -
simply does not follow. The machines may not want to
manipulate humans.
Hutter then argues that intelligent agents are likely to resist
wireheading themselves - because of the long-term catastrophic
consequences of doing so. I do not really agree with this argument
either. Wireheading is often bad - but it is not necessarily
completely catastrophic. History shows us many heroin addicts who
still managed to live out their lives and contribute to society - Anna
Kavan, William Burroughs - and so on. It is possible to be a
drug addict and keep it together enough to sustainably ensure
your next fix. Much the same applies to wireheading.
A far-sighted wireheading agent may be better than nothing - but it
is still a disaster that should have been avoided.
AIXI appears to be vulnerable to wireheading to me - because of its
reward architecture.
Depending on the details of the temporal discounting architecture, it
might avoid catastrophic wireheading - and so avoid becoming
a total vegetable - but it could still become enough of a
wirehead to turn into a dangerous psychopath, addicted to its own
pleasure.
There is a way to avoid the wirehead problem - don't
build agents to value pleasure above all else in the first place.
Instead of hitting them with sticks to teach them their aim in life,
you build their goals into them.
The third problem is not so serious.
AIXI is a serial agent, modelled by a Turing machine. The world
actually works in parallel. In many areas, you can simulate a parallel
machine with a serial one, so the details of the serial abstraction
drop out of the model, and cause no damage.
However, the scalar reward channel in AIXI is just not a sensible
model for an intelligent agent. If you look at humans, pleasure and
pain are nuanced - and stream in on multiple channels simultaneously.
A single scalar reward channel seems like an impoverished model for
such an agent.
The fourth and final problem concerns Solomonoff induction.
This problem is also not very serious.
Solomonoff induction is a formalised version of Occam's Razor using Kolmogorov
complexity - and it is what AIXI uses to prune its model of the
world.
Unfortunately, Kolmogorov complexity is a language-dependent metric.
The usual excuse for ignoring this - that an interpreter for another
language takes a constant number of bits - simply doesn't wash.
The best formulation of Occam's Razor is not known. Indeed,
it is not even known if a formulation of the razor in terms of a
single descriptive language is optimal.
It has been argued that AIXI means that we would know how to build
highly-intelligent machines, if we had inexpensive-enough computing
power:
[footage of Ben Goertzel]
I don't think the conclusion here is correct - while of obvious value,
AIXI has some serious issues, and represents a rather poor existence
proof of the concept of a superintelligent machine.